
简介
SOLiD 4测序系统是由ABI公司研发的新一代超高通量基因测序分析系统,可运用到多个领域。该系统采用结合在磁珠上单分子DNA片段簇为测序模板,以四色荧光标 记寡核苷酸进行连续的连接反应为基础,对扩增的DNA片段进行大规模高通量测序。与聚合酶测序方法不同的是,SOLiD系统利用专利的逐步连接 (stepwiseligation)技术来产生高质量的数据,可应用于全基因组测序、染色质免疫共沉淀(ChIP)、微生物测序、数字核型分析、临床 测序、基因型分析、基因表达分析和小分子RNA的发现等等。
技术特点
1.无以伦比的通量:100Gb的数据/run;
2.高准确率:准确率>99.94%;
3.全自动的操作平台,省时,高效,准确: 每道每天可产生100 Mreads,15Gb/每天;
4.系统的灵活性:两个独立控制的流动池,可以进行一张或二张玻片的同时分析。开放式高密度磁珠沉置,每张玻片可分为1个,4个或8个测序区域,支持多重技术Barcode。
5.应用广泛灵活:超高通量的数据支持大规模测序和结构变异性分析。独特的 双碱基编码特性使系统具备自检功能,对单核苷酸多态性(SNP)的检测精确率可以达到最高。以最大通量的标签实验为应用的基础,可以为全转录组、染色质免 疫共沉淀(ChIP)和小RNA,甲基化研究等提供高度敏感的检测方法。
6.强大的生物信息软件支持和技术支持
检测原理
1.文库制备(根据实验设计进行)
*随机片段文库(fragment library)
*末端配对文库(mate-paired library)
2.emPCR(乳滴PCR)/微珠富集在已加入模板,PCR反应元件,微珠和引物的微反应器中进行Clonal bead populations(克隆微珠群体)的制备。PCR完成之后使模板变性,并进行微珠富集以筛选带有延伸模板的微珠。微珠上的模板经过3‘端修饰,使之 可以共价结合到玻片上。
3.微珠沉积将3’末端修饰的微珠沉积在一块玻片上。
4.通过连接反应进行测序引物与文库模板上的P1接头序列杂交,一套四色荧光标记的双碱基探针竞相与测序引物连接。经一系列循环的连接检测和切割,测序反应逐步进行。
5.引物重置
每一核酸片段均与五轮引物重置完成一个序列标签。
检测服务流程
1,样本检测
2,样品文库制备
3,上机测序
4,数据分析
5,交付数据
应用领域
1. DNA测序
2. RNA测序
1)转录本测序
2)小RNA测序
3. 甲基化测序
1)重硫酸盐处理测序
2)MeDIP测序
1.SOLiD关键技术及其原理
SOLiD使用连接法测序获得基于“双碱基编码原理”的 SOLiD颜色编码序列,随后的数据分析比较原始颜色序列与转换成颜色编码的reference序列,把SOLiD颜色序列定位到reference上, 同时校正测序错误,并可结合原始颜色序列的质量信息发现潜在SNP位点。
1.1. SOLiD文库构建
使 用SOLiD测序时,可根据实际需要,制备片段文库(fragment library)或末端配对文库(mate-paired library)。简单地说,制备片段文库就是在短DNA片段(60~110 bp)两端加上SOLiD接头(P1、P2 adapter)。而制备末端配对文库,先通过DNA环化、Ecop15I酶切等步骤截取长DNA片段(600bp到10kb)两末端各25 bp进行连接,然后在该连接产物两端加上SOLiD接头。两种文库的最终产物都是两端分别带有P1、P2 adapter的DNA双链,插入片段及测序接头总长为120~180 bp。
1.2:油包水PCR
我 们知道,文库制备得到大量末端带P1、P2 adapter但内部插入序列不同的DNA双链模板。和普通PCR一样,油包水PCR也是在水溶液进行反应,该水相含PCR所需试剂,DNA模板及可分别 与P1、P2 adapter结合的P1、P2 PCR引物。但与普通PCR不同的是,P1引物固定在P1磁珠球形表面 (SOLiD将这种表面固定着大量P1引物的磁珠称为P1磁珠)。PCR反应过程中磁珠表面的P1引物可以和变性模板的P1 adapter负链结合,引导模板合成,这样一来,P1引物引导合成的DNA链也就被固定到P1磁珠表面了。
油包水PCR最大的特点 是可以形成数目庞大的独立反应空间以进行DNA扩增。其关键技术是“注水到油”,基本过程是在PCR反应前,将包含PCR所有反应成分的水溶液注入到高速 旋转的矿物油表面,水溶液瞬间形成无数个被矿物油包裹的小水滴。这些小水滴就构成了独立的PCR反应空间。理想状态下,每个小水滴只含一个DNA模板和一 个P1磁珠,由于水相中的P2引物和磁珠表面的P1引物所介导的PCR反应,这个DNA模板的拷贝数量呈指数级增加,PCR反应结束后,P1磁珠表面就固 定有拷贝数目巨大的同来源DNA模板扩增产物。ABI公司提供的SOLiD实验手册已经把小水滴体积及水相中DNA模板和磁珠的个数比等重要参数进行了技 术优化和流程固定,尽可能提高“优质小水滴”(水滴中只含一个DNA模板一个P1磁珠)的数量,为后续SOLiD测序提供只含有一种DNA模板扩增产物的 高质量P1磁珠。
1.3.含DNA模板P1磁珠的固定
SOLiD测序反应在SOLiD玻片表面进行。含有DNA模板的P1磁珠共价结合在SOLiD玻片表面。磁珠是SOLiD测序的最小单元。每个磁珠SOLiD测序后形成一条序列(具体SOLiD测序过程请见图5)。
1.4. SOLiD双碱基编码原理及测序流程
SOLiD “双碱基编码原理”实质上是阐明了荧光探针的颜色类型与探针编码区碱基对的对应关系。SOLiD连接反应的底物是8碱基单链荧光探针混合物。连接反应中, 这些探针按照碱基互补规则与单链DNA模板链配对。如图1“底物探针”所示,探针5’末端可分别标记“CY5,Texas Red,CY3,6-FAMTM”4种颜色的荧光染料,并且这四种颜色用数字“3,2,1,0”示意;探针3’端1~5位为随机碱基,可以是 “A,T,C,G”四种碱基中的任何一种碱基,其中第1、2位构成的碱基对是表征探针染料类型的编码区,“双碱基编码矩阵”规定了该编码区16种碱基对和 4种探针颜色的对应关系,而3~5位的“n”表示随机碱基,6~8位的“z”指的是可以和任何碱基配对的特殊碱基,由上可知,SOLiD连接反应底物中共 有45 种底物探针。
单向SOLiD测序包括五轮测序反应。每轮测序反应含有多次连接反应(一般情况下,片段文库是7次,mate- paired文库是5次,所以片段文库共有35个连接反应,而末端配对文库共有25次连接反应)。每轮测序反应的第一次连接反应由与P1引物区域互补的 “连接引物”介导。这五种连接引物长度相同,但在P1引物区域的位置相差一个碱基(分别用n,n-1,n-2,n-3,n-4表示),都含有5’端磷酸, 所以可以介导连接反应的进行。现以图5所示一个磁珠上发生的SOLiD测序反应为例进行说明。第一轮测序的第一次连接反应由连接引物“n”介导,由于每个 磁珠只含有均质单链DNA模板(也就是每个磁珠表面的单链DNA模板序列都是一样的),所以这次连接反应掺入一种8碱基荧光探针,SOLiD测序仪记录反 应模板序列第1、2位碱基序列的探针第1、2位编码区颜色信息,随后的化学处理断裂探针3’端第5、6位碱基间的化学键,并除去6~8位碱基及5’末端荧 光基团,暴露探针第5位碱基5’磷酸,为下一次连接反应作准备。由此我们知道第一次连接反应使合成链多了5个碱基,所以第二次连接反应得到反应模板序列第 6、7位碱基序列的颜色信息,而第三次连接反应得到的是第11、12位碱基序列的颜色信息… … 以此类推,第一轮测序反应获取了模板链7个碱基对的颜色信息。如图5所示,由于第二轮连接引物n-1比第一轮错开一位,所以第二轮得到是以0,1位起始的 7个碱基对的颜色信息。五轮测序反应反应后,按照第0、1位,第1、2位... …的顺序把对应于模板序列的颜色信息连起来,就得到由“0,1,2,3”组成的SOLiD原始颜色序列。
1.5. 数据分析原理
SOLiD 测序完成后,获得了由颜色编码组成的SOLiD原始序列(图6.a)。理论上来说,按照“双碱基编码矩阵”(图4),只要知道所测DNA序列中任何一个位 置的碱基类型,就可以将SOLiD原始颜色序列“解码”成碱基序列。但由于双碱基编码规则中双碱基与颜色信息的兼并特性(一种颜色对应4种碱基对),前面 碱基的颜色编码直接影响紧跟其后碱基的解码,所以一个错误颜色编码就会引起“连锁解码错误”,改变错误颜色编码之后的所有碱基(图6.1)。
和 所有其它测序仪一样,测序错误在所难免,关键是对测序错误的评价和后续处理。为避免“连锁解码错误”的发生,SOLiD数据分析软件不直接将SOLiD原 始颜色序列解码成碱基序列,而是依靠reference序列进行后续数据分析。SOLiD序列分析软件首先根据“双碱基编码矩阵”把reference碱 基序列转换成颜色编码序列,然后与SOLiD原始颜色序列进行比较,来获得SOLiD原始颜色序列在reference的位置,及两者的匹配性信息。 Reference转换而成的颜色编码序列和SOLiD原始序列的不完全匹配主要有两种情况:“单颜色不匹配”和“两连续颜色不匹配”(图6)。由于每个 碱基都被独立地检测两次(图5),且SNP位点将改变连续的两个颜色编码(图6.2),所以一般情况下SOLiD将单颜色不匹配处理成测序错误,这样一 来,SOLiD分析软件就完成了该测序错误的自动校正;而连续两颜色不匹配也可能是连续的两次测序错误,SOLiD分析软件将综合考虑该位置颜色序列的一 致性及质量值来判断该位点是否为SNP。
2.SOLiD测序技术的应用
2.1. 基因组测序
全基因组重测序。研究者可以基因组DNA为初始样本构建SOLiD文库(fragment文库及mate-paired文库),以恰当的全基因组序列为reference,可以快速鉴定SNP,indel及基因组结构变化。
特 定基因组区域测序。除应用于传统的ChIP-seq,SOLiD技术平台还可以结合芯片技术,富集特定基因组序列进行深度测序,快速鉴定SNP。其关键技 术流程如下:SOLiD fragment文库经适当循环数PCR扩增得到足量样品DNA(约30ug), 文库扩增产物与Agilent芯片(或其它自订制芯片)杂交,然后对芯片探针紧密结合的洗脱产物进行常规Emulsion PCR及SOLiD测序。SOLiD结合芯片技术对基因组特定区域的进行深度测序,可发现低频率SNP(如肿瘤样本中特定基因的体细胞突变)。
2.2. RNA-seq
高 通量测序仪的问世,使得测序成本大大降低,提供了不依赖现有基因模型的大规模基因表达谱研究手段,促进了针对细胞全部转录产物(small RNA 等non-coding RNA,低拷贝protein-coding RNA及其可变剪接体)的深度挖掘及后续功能研究。
目前有两 种SOLiD试剂盒促进SOLiD测序仪在转录组上的应用。SOLiD small RNA 试剂盒以含5’段磷酸及3’段羟基的small RNA为初始样本,2天就可完成与SOLiD RNA特异adapter连接,逆转录,PCR扩增等步骤, 得到SOLiD fragment 文库。SOLiD whole transcriptome expression试剂盒针对序列较长的non-coding RNA或mRNA。该试剂盒使用RNA H将mRNA或去除rRNA的总RNA片段化并回收酶切产物,其后实验流程和SOLiD small RNA完全相同。这两种试剂盒以RNA为初始样本,并且所用的RNA 特异adapter方向确定,所以最后测序所得序列的方向也就确定了。而传统方法大多以双链cDNA为初始样本,难以确定测序所得序列来自转录本的正义链 还是反义链而干扰后续数据分析。同时,SOLiD强大的测序能力,使得高通量发掘低拷贝转录本成为可能。
3. 基因组所SOLiD测序仪运行情况
目 前,ABI公司针对我所SOLiD实验小组的技术培训基本结束。SOLiD实验小组已经具备独立构建基因组片段文库和末端配对文库的能力,所构建文库各项 质量指标基本符合要求。作为ABI高级客户,我们获得了SOLiD small RNA 和SOLiD whole transcriptome expression试剂盒各一个。相关转录组学实验正在进行中。
The Applied Biosystems SOLiD 4 System is a revolutionary genetic analysis platform that enables massively parallel sequencing of clonally-amplified DNA fragments linked to beads. The sequencing methodology is based on sequential ligation with dye-labeled oligonucleotides. The SOLiD 4 System enables researchers to obtain higher-quality genomes at lower cost without the purchase of a new instrument. With Applied Biosystems, researchers experience peace of mind.
- Scalable system
- Superior accuracy
- Uniform coverage
- True Barcoded paired-end sequencing
- Automated sample preparation
Scalable
The SOLiD 4 System’s open slide format and flexible bead densities enable increases in throughput with protocol and chemistry optimizations. While competitive technologies are already near, or have achieved maximum throughput, the SOLiD 4 System has room for throughput advancements utilizing the same platform.
Accurate
With system accuracy greater than 99.94%, due to 2 base encoding, the SOLiD 4 System distinguishes itself by providing data that is significantly more accurate than alternative next-generation platforms for variation detection. 2 Base encoding enables unique error checking capability, providing higher confidence in each call. With the SOLiD 4 System, scientists can focus on the biological significance of their results rather than sifting through poor quality data. (see figure 2)
High Throughput
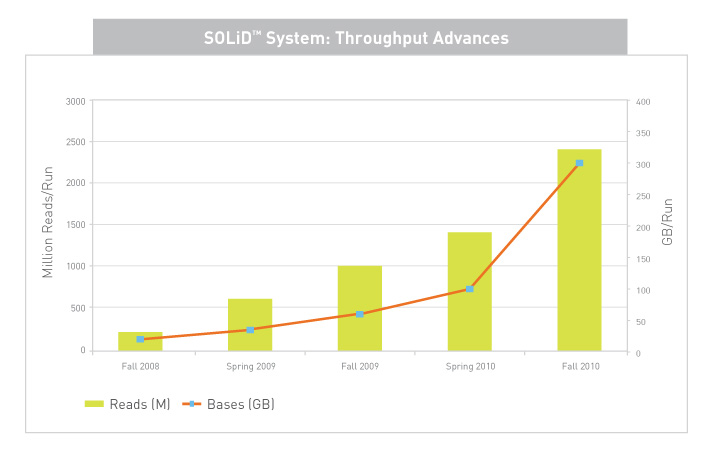
The SOLiD 4 System generates over 100 gigabases and 1.4 billion tags per run (extendable to 300 GB and 2.4 Billion tags per run), which is more usable data than any other next-generation system available today. This level of throughput enables large scale resequencing and tag based experiments to be completed more cost effectively than ever before.
Flexible
The independent flow cell configuration of the SOLID Analyzer enables users to run two completely independent experiments in a single run– essentially providing 2 instruments in one (see figure 3). For example, scientists can analyze both sequencing and expression experiments, or sequence multiple mate paired libraries with different insert sizes in a single run.

Mate Pairs
The SOLiD 4 System supports sample preparation for mate-paired libraries with insert sizes ranging from 600 bp up to 10 kbp. This broad range of insert sizes combined with ultra high throughput and flexible 2 flow cell configuration enables more precise characterization of structural variation across the genome.
How it Works

Start with a fragment or mate-paired library depending on the application and information you need. Prepare clonal bead populations in microreactors containing template, PCR reaction components, beads and primers. After PCR, you denature the templates and perform a bead enrichment step to separate beads with extended templates from undesired beads. Then deposit the 3’ modified beads onto a glass slide. Once loaded onto the Analyzer, primers hybridize to the adapter sequence within the library template. A set of four fluorescently labeled di-base probes compete for ligation to the sequencing primer. Specificity of the di-base probe is achieved by interrogating every 1st and 2nd base in each ligation reaction. Multiple cycles of ligation, detection and cleavage are performed with the number of cyclers determining the eventual read length. Following a series of ligation cycles, the extension product is removed and the template is reset with a primer complementary to the n-1 position for a second round of ligation cycles. Five rounds of primer reset are completed for each sequence tag. For mate-paired libraries, the entire process is repeated. (see figure 4)
Extensive Support
With over 8,000 global service and support personnel, Applied Biosystems has the most extensive network of experienced Field Application Specialists (FAS) and Support Engineers to work with you. With the SOLiD 4 System, there is a dedicated team of engineers, application specialist and informatics support that will be there when and where you need us most. |